Redis(Remote Dictionary Server)是一个使用ANSI C编写的开源、支持网络、基于内存、分布式、可选持久性的键值对存储数据库。
Linux 下的安装
官网下载最新稳定版本:Redis
1
2
3
4
|
wget http://download.redis.io/releases/redis-6.0.8.tar.gz
tar -zxvf redis-6.0.8.tar.gz
cd redis-6.0.8
make
|
执行完 make 命令后,redis-6.0.8 的 src 目录下会出现编译后的 redis 服务程序 redis-server,还有用于测试的客户端程序 redis-cli。
默认配置启动:
1
2
|
cd src
./redis-server
|
自定义配置文件启动:
1
2
|
cd src
./redis-server ../custom/redis.conf
|
检查 redis 是否正常启动(同样适用其他软件):
1
2
3
4
|
[root@VM-16-16-centos ~]# ps -ef | grep redis
root 17602 20682 0 11:48 pts/0 00:00:00 grep --color=auto redis
polkitd 29312 29296 0 Jul16 pts/0 00:01:18 redis-server *:6379
root 29628 29546 0 Jul16 ? 00:00:00 redis-cli
|
启动 redis 服务进程后,就可以使用测试客户端程序 redis-cli 和redis服务交互了:
1
2
3
4
5
6
|
./redis-cli
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> dbsize
(integer) 1
127.0.0.1:6379>
|
性能测试工具
redis-benchmark是自带的性能测试工具,方便我们轻松掌握服务器配置后的性能指标,支持以下参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
Usage: redis-benchmark [-h <host>] [-p <port>] [-c <clients>] [-n <requests]> [-k <boolean>]
-h <hostname> Server hostname (default 127.0.0.1)
-p <port> Server port (default 6379)
-s <socket> Server socket (overrides host and port)
-a <password> Password for Redis Auth
-c <clients> Number of parallel connections (default 50)
-n <requests> Total number of requests (default 100000)
-d <size> Data size of SET/GET value in bytes (default 2)
--dbnum <db> SELECT the specified db number (default 0)
-k <boolean> 1=keep alive 0=reconnect (default 1)
-r <keyspacelen> Use random keys for SET/GET/INCR, random values for SADD
Using this option the benchmark will expand the string __rand_int__
inside an argument with a 12 digits number in the specified range
from 0 to keyspacelen-1. The substitution changes every time a command
is executed. Default tests use this to hit random keys in the
specified range.
-P <numreq> Pipeline <numreq> requests. Default 1 (no pipeline).
-q Quiet. Just show query/sec values
--csv Output in CSV format
-l Loop. Run the tests forever
-t <tests> Only run the comma separated list of tests. The test
names are the same as the ones produced as output.
-I Idle mode. Just open N idle connections and wait.
|
通常使用以下命令进行测试即可:
1
|
redis-benchmark -q -n 100000
|
效果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
root@61b96dd72482:/data# redis-benchmark -q -n 100000
PING_INLINE: 27525.46 requests per second, p50=1.471 msec
PING_MBULK: 28636.88 requests per second, p50=1.415 msec
SET: 28003.36 requests per second, p50=1.447 msec
GET: 27240.53 requests per second, p50=1.479 msec
INCR: 27979.86 requests per second, p50=1.479 msec
LPUSH: 27270.25 requests per second, p50=1.487 msec
RPUSH: 27987.69 requests per second, p50=1.463 msec
LPOP: 27670.17 requests per second, p50=1.479 msec
RPOP: 27548.21 requests per second, p50=1.479 msec
SADD: 24021.14 requests per second, p50=1.471 msec
HSET: 26546.32 requests per second, p50=1.487 msec
SPOP: 27862.91 requests per second, p50=1.439 msec
ZADD: 27277.69 requests per second, p50=1.487 msec
ZPOPMIN: 28288.54 requests per second, p50=1.431 msec
LPUSH (needed to benchmark LRANGE): 26759.43 requests per second, p50=1.495 msec
LRANGE_100 (first 100 elements): 14900.91 requests per second, p50=2.175 msec
LRANGE_300 (first 300 elements): 6345.98 requests per second, p50=5.303 msec
LRANGE_500 (first 500 elements): 4289.82 requests per second, p50=7.503 msec
LRANGE_600 (first 600 elements): 3748.13 requests per second, p50=8.271 msec
MSET (10 keys): 23228.80 requests per second, p50=1.703 msec
|
Redis是单线程的,但是也是很快的,它是基于内存操作的,将所有数据都放在内存中的。CPU不是它的性能瓶颈,它的性能主要和网络带宽和内存相关。多线程切换是需要切换上下文的,是耗时的操作。
基础知识
Redis默认有 16 个数据库,默认使用的是第一个,可以使用select切换数据库:
1
2
3
4
5
6
|
root@61b96dd72482:/data# redis-cli
127.0.0.1:6379> select 3
OK
127.0.0.1:6379[3]> dbsize #查看DB大小
(integer) 0
127.0.0.1:6379[3]>
|
查看所有key使用keys *命令:
1
2
3
|
127.0.0.1:6379[1]> keys * #查看数据库所有命令
(empty array)
127.0.0.1:6379[1]>
|
清空数据有两个命令:清楚当前数据库flushdb, 清楚所有数据库flushall。
1
2
3
4
5
|
127.0.0.1:6379[1]> flushdb
OK
127.0.0.1:6379[1]> flushall
OK
127.0.0.1:6379[1]>
|
五大数据类型
Redis是一个开源(BSD)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件 MQ。它支持多种数据结构:字符串(strings),散列(hashes),列表(lists),集合(sets),有序集合(sorted sets)与范围查询,bitmaps,hyperloglogs和地理空间(geospatial)索引半径查询。Redis内置了复制,LUA 脚本,LRU 驱动事件,事务和不同级别的磁盘持久化,并通过哨兵和自动分区提供高可用性。
Redis-Key
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
127.0.0.1:6379> set name brein
OK
127.0.0.1:6379> exists name #是否存在
(integer) 1
127.0.0.1:6379>
#设置10秒过期
127.0.0.1:6379> set order abcd
OK
127.0.0.1:6379> expire order 10 #10是秒数
(integer) 1
127.0.0.1:6379> ttl order #查看还剩几秒
(integer) 6
127.0.0.1:6379> ttl order
(integer) 4
127.0.0.1:6379> ttl order
(integer) 3
127.0.0.1:6379> ttl order
(integer) -2
127.0.0.1:6379> exists order
(integer) 0
127.0.0.1:6379> get order
(nil)
127.0.0.1:6379>
#移动数据到别的库
127.0.0.1:6379> set age 18
OK
127.0.0.1:6379> get age
"18"
127.0.0.1:6379> move age 1 #1为要移动到的库
(integer) 1
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> get age
"18"
127.0.0.1:6379[1]>
#删除数据
127.0.0.1:6379[1]> del age
(integer) 1
127.0.0.1:6379[1]> get age
(nil)
127.0.0.1:6379[1]>
#查看类型
127.0.0.1:6379> keys *
1) "age"
2) "name"
127.0.0.1:6379> type name
string
127.0.0.1:6379> type age
string
127.0.0.1:6379>
|
字符串类型(string)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
|
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> set key1 v1
OK
127.0.0.1:6379> append key1 v2 # 追加v2到key1中 key若不存在就相当于set key
(integer) 4
127.0.0.1:6379> get key1
"v1v2"
127.0.0.1:6379> strlen key1 # 取得key1中的数据长度
(integer) 4
#增加,减少 incr decr incrby decrby
127.0.0.1:6379> set views 0
OK
127.0.0.1:6379> get views
"0"
127.0.0.1:6379> incr views
(integer) 1
127.0.0.1:6379> get views
"1"
127.0.0.1:6379> decr views
(integer) 0
127.0.0.1:6379> get views
"0"
127.0.0.1:6379> incrby views 10 #步长 10
(integer) 10
127.0.0.1:6379> get views
"10"
127.0.0.1:6379> decrby views 5
(integer) 5
127.0.0.1:6379> get views
"5"
#######################################################################################
#字符串范围
127.0.0.1:6379> get key1
"hello, brein"
127.0.0.1:6379> getrange key1 0 4 #截取字符串[0, 3]
"hello"
127.0.0.1:6379> getrange key1 0 -1 #获取全部字符串
"hello, brein"
#替换
127.0.0.1:6379> setrange key1 0 zbx: #替换指定位置开始的字符串
(integer) 12
127.0.0.1:6379> get key1
"zbx:o, brein"
# setex (set with expire) #设置过期时间
# setnx (set if not exist) # 如果不存在才设置(在分布式锁中常常用到)
127.0.0.1:6379> setex key2 30 "hello"
OK
127.0.0.1:6379> ttl key2
(integer) 18
127.0.0.1:6379> ttl key2
(integer) -2
127.0.0.1:6379> setnx key2 "brein" #如果不存在则创建,如果存在则失败
(integer) 1
127.0.0.1:6379> get key2
"brein"
127.0.0.1:6379>
#同时设置多个,利用mset mget
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3
OK
127.0.0.1:6379> keys *
1) "k2"
2) "k3"
3) "k1"
127.0.0.1:6379> mget k1 k2 k3
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> msetnx k1 v1 k4 v4 #因为msetnx是原子操作,因为已经存在k1,所以报错,k4也不会存入
(integer) 0
127.0.0.1:6379> get k4
(nil)
#对象
127.0.0.1:6379> set user:1 {name:brein, age:18} #json字符串中不可以有空格
(error) ERR syntax error
127.0.0.1:6379> set user:1 {name:brein,age:18} #设置一个user:1对象,值为json字符串
OK
# getset -> 先get再set
127.0.0.1:6379> keys *
1) "article:2:views"
2) "user:1:age"
3) "user:1"
4) "user:1:name"
5) "article:1:views"
127.0.0.1:6379> getset db redis #如果不存在key,则返回nil
(nil)
127.0.0.1:6379> get db
"redis"
127.0.0.1:6379> getset db mongodb #如果存在key,获取原来的的值,并设置现在的新值
"redis"
127.0.0.1:6379> get db
"mongodb"
|
注意Redis中key的设计是很灵活的,如下面的形式是完全可以的:
1
2
3
4
5
|
127.0.0.1:6379> mset article:1:views 1000 article:2:views 200
OK
127.0.0.1:6379> mget article:1:views article:2:views
1) "1000"
2) "200"
|
列表(List)
在Redis中可以把List作成堆栈(lpush lpop),队列(lpush rpop),阻塞队列。所有list相关命令都以l开头
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
|
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379> lpush list one #从左边插入
(integer) 1
127.0.0.1:6379> lpush list two
(integer) 2
127.0.0.1:6379> lpush list three
(integer) 3
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> lrange list 0 1
1) "three"
2) "two"
127.0.0.1:6379> rpush list four #从右边插入
(integer) 4
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "two"
3) "one"
4) "four"
#lpop rpop
127.0.0.1:6379> lpop list
"three"
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
3) "four"
127.0.0.1:6379> rpop list
"four"
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
#lindex
127.0.0.1:6379> lindex list 0
"two"
127.0.0.1:6379> lindex list 1
"one"
#移除指定值
127.0.0.1:6379> lpush l2 one
(integer) 1
127.0.0.1:6379> lpush l2 two
(integer) 2
127.0.0.1:6379> lpush l2 three
(integer) 3
127.0.0.1:6379> lpush l2 four
(integer) 4
127.0.0.1:6379> lpush l2 four
(integer) 5
127.0.0.1:6379> lpush l2 four
(integer) 6
127.0.0.1:6379> lrange l2 0 -1
1) "four"
2) "four"
3) "four"
4) "three"
5) "two"
6) "one"
127.0.0.1:6379> lrem l2 1 one # lrem key count item
(integer) 1
127.0.0.1:6379> lrange l2 0 -1
1) "four"
2) "four"
3) "four"
4) "three"
5) "two"
127.0.0.1:6379> lrem l2 2 four #list中数据可以重复,此处移除list中2个four
(integer) 2
127.0.0.1:6379> lrange l2 0 -1
1) "four"
2) "three"
3) "two"
#截断
127.0.0.1:6379> lrange l1 0 -1
1) "six"
2) "five"
3) "four"
4) "three"
5) "two"
6) "one"
7) "four"
8) "three"
#index 是从上到下的 l第一个位置是0 r第一个位置是len-1
127.0.0.1:6379> lrange l1 0 0 #这样可以取得list中某个位置的值
1) "six"
127.0.0.1:6379> lrange l1 0 1
1) "six"
2) "five"
127.0.0.1:6379> ltrim l1 1 6 #截取从位置1到位置6的值,截取后list变为截取的新的list
OK
127.0.0.1:6379> lrange l1 0 -1
1) "five"
2) "four"
3) "three"
4) "two"
5) "one"
6) "four"
#rpoplpush 移除最后一个元素,并移动到新的列表中
127.0.0.1:6379> rpoplpush l1 l2
"four"
127.0.0.1:6379> lrange l1 0 -1
1) "five"
2) "four"
3) "three"
4) "two"
5) "one"
127.0.0.1:6379> lrange l2 0 -1
1) "four"
#lset 将列表中指定下标的值替换为另外一个值,相当于更新
127.0.0.1:6379> exists list
(integer) 0
127.0.0.1:6379> lset list 0 item # 注意:列表必须存在才可以使用lset
(error) ERR no such key
127.0.0.1:6379> lpush list value1
(integer) 1
127.0.0.1:6379> lset list 0 one
OK
127.0.0.1:6379> lrange list 0 0
1) "one"
127.0.0.1:6379> lset list 1 two #列表中必须有指定的index才可以更新,否则报错
(error) ERR index out of range
#linsert 格式:linsert key before|after pivot value
127.0.0.1:6379> linsert list before one hahaha
(integer) 2
127.0.0.1:6379> lrange list 0 -1
1) "hahaha"
2) "one"
|
小结
- 列表实际上是一个链表,
before node,after node, left, right都可以插入值
- 如果
key不存在,创建新的链表
- 如果
key存在,新增内容
- 如果移除所有值,空链表,也代表不存在
- 在两边插入或者修改值,效率是最高的,中间元素效率会低一些
集合(set)
SET中的值是不能重复的。它是无序的。
下面是集合相关操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
127.0.0.1:6379> sadd s1 hello #插入一个值
(integer) 1
127.0.0.1:6379> sadd s1 hello #不能重复插入
(integer) 0
127.0.0.1:6379> smembers s1 #显示集合中的所有值
1) "hello"
127.0.0.1:6379> sadd s1 world
(integer) 1
127.0.0.1:6379> sismember s1 hello #判断一个值是否在集合中,在返回1,不在返回0
(integer) 1
127.0.0.1:6379> sismember s1 brein
(integer) 0
127.0.0.1:6379> scard s1 #获取集合中的元素个数
(integer) 2
127.0.0.1:6379> sadd s1 remove_item
(integer) 1
127.0.0.1:6379> smembers s1
1) "world"
2) "hello"
3) "remove_item"
127.0.0.1:6379> srem s1 remove_item #移除集合中的指定元素
(integer) 1
127.0.0.1:6379> smembers s1
1) "world"
2) "hello"
127.0.0.1:6379> sadd s1 item1 item2 item3 #插入多个元素
(integer) 3
127.0.0.1:6379> smembers s1
1) "world"
2) "hello"
3) "item2"
4) "item1"
5) "item3"
127.0.0.1:6379> SRANDMEMBER s1 #随机抽取一个元素
"item3"
127.0.0.1:6379> SRANDMEMBER s1 2 #随机抽取指定个数的元素
1) "world"
2) "item2"
127.0.0.1:6379> SPOP s1 #随机删除一个元素
"hello"
127.0.0.1:6379> SPOP s1 2 #随机删除指定个数的元素
1) "item1"
2) "world"
#将一个指定的值移动到另外一个集合中
127.0.0.1:6379> SMEMBERS s1
1) "item2"
2) "item3"
127.0.0.1:6379> sadd s2 item1
(integer) 1
127.0.0.1:6379> SMOVE s1 s2 item2 #移动指定值 smove source destination element
(integer) 1
127.0.0.1:6379> SMEMBERS s1
1) "item3"
127.0.0.1:6379> SMEMBERS s2
1) "item2"
2) "item1"
#实际业务中可能存在类似“共同关注” “共同好友”这样的需求,可以利用SET的交集计算
127.0.0.1:6379> SMEMBERS s1
1) "c"
2) "a"
3) "b"
127.0.0.1:6379> SMEMBERS s2
1) "d"
2) "c"
3) "e"
127.0.0.1:6379> sdiff s1 s2 #差集
1) "a"
2) "b"
127.0.0.1:6379> SINTER s1 s2 #交集
1) "c"
127.0.0.1:6379> SUNION s1 s2 #并集
1) "c"
2) "a"
3) "b"
4) "d"
5) "e"
|
哈希(hash)
可以是单个值操作:hset key field value
同时设置多个值时,类似MAP集合:hset/hmset key field1 value1 field2 value2...
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
127.0.0.1:6379> hset hash1 item1 value1 item2 value2
(integer) 2
127.0.0.1:6379> hget hash1 item1
"value1"
127.0.0.1:6379> HGETALL hash1 #获取全部
1) "item1"
2) "value1"
3) "item2"
4) "value2"
127.0.0.1:6379> hmset hash2 item1 value1 item2 value2 #hset hmset 这里一样
OK
127.0.0.1:6379> hgetall hash2
1) "item1"
2) "value1"
3) "item2"
4) "value2"
127.0.0.1:6379> hmget hash2 item1 item2 # hmget获取多个值
1) "value1"
2) "value2"
127.0.0.1:6379> hdel hash2 item1 item2 # hdel删除一个或者多个
(integer) 2
127.0.0.1:6379> HGETALL hash2
(empty array)
127.0.0.1:6379> hlen hash1 # hlen取得长度
(integer) 2
127.0.0.1:6379> HEXISTS hash1 item1 #判断是否存在
(integer) 1
127.0.0.1:6379> HKEYS hash1 #获取所有key
1) "item1"
2) "item2"
127.0.0.1:6379> HVALS hash1 #获取说有值
1) "value1"
2) "value2"
127.0.0.1:6379> hset hash1 item3 6
(integer) 1
127.0.0.1:6379> HINCRBY hash1 item3 4 #增加指定key的value
(integer) 10
127.0.0.1:6379> HINCRBY hash1 item3 -5 #减少指定key的value
(integer) 5
127.0.0.1:6379> HSETNX hash1 item4 hello #如果不存在,则可以设置
(integer) 1
127.0.0.1:6379> HSETNX hash1 item4 world #如果存在,则不可以设置
(integer) 0
127.0.0.1:6379> HGETALL hash1
1) "item1"
2) "value1"
3) "item2"
4) "value2"
5) "item3"
6) "5"
7) "item4"
8) "hello"
|
哈希表可以用在存储对象之类的数据上。比如存储用户数据:
| KEY |
Field-Value |
user:1 |
field: name value: brein / field: age value: 18 |
user:2 |
field: name value: zs / field: age value: 8 |
有序集合(Zset)
在SET的基础上增加了一个值,SET k1 v1 => zset k1 score1 v1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
127.0.0.1:6379> zadd zset1 1 one
(integer) 1
127.0.0.1:6379> zadd zset1 2 two 3 three
(integer) 2
127.0.0.1:6379> ZRANGE zset1 0 -1
1) "one"
2) "two"
3) "three"
#ZRANGEBYSCORE key min max [withscores]
127.0.0.1:6379> zadd salary 25000 brein 5000 zhangsan 8000 lisi
(integer) 3
127.0.0.1:6379> ZRANGE salary 0 -1
1) "zhangsan"
2) "lisi"
3) "brein"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf #显示全部 从小到大
1) "zhangsan"
2) "lisi"
3) "brein"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf withscores #显示全部并附带score
1) "zhangsan"
2) "5000"
3) "lisi"
4) "8000"
5) "brein"
6) "25000"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf 8000 withscores # max=8000
1) "zhangsan"
2) "5000"
3) "lisi"
4) "8000"
127.0.0.1:6379> ZREVRANGE salary 0 -1 withscores # 降序排列
1) "brein"
2) "25000"
3) "lisi"
4) "8000"
5) "zhangsan"
6) "5000"
127.0.0.1:6379> ZCOUNT salary 0 20000 #指定区间的数量
(integer) 2
127.0.0.1:6379> zadd zset1 9000 wangwu
(integer) 1
127.0.0.1:6379> ZRANGE zset1 0 -1
1) "one"
2) "two"
3) "three"
4) "wangwu"
127.0.0.1:6379> ZCARD zset1 #显示元素个数
(integer) 4
127.0.0.1:6379> ZREM zset1 wangwu #移除元素
(integer) 1
127.0.0.1:6379> ZRANGE zset1 0 -1
1) "one"
2) "two"
3) "three"
|
应用场景
- 存储成绩表 ,工资表排序
- 带权重的判断,普通消息,重要消息,错误消息
- 实时的排行榜,取 TOP N
三种特殊数据类型
Geospatial 地理位置
应用:朋友位置,附近的人(推算方圆几里的人),打车地图地理位置距离计算等等(推算两地之间的距离)
Hyperloglog 基数统计
占用内存是固定的,只需要12kb内存。从内存角度看,hyperloglog就是首选。
什么是基数?
A { 1, 3, 5, 7, 8, 9}
B { 1, 3, 5, 7, 8}
基数(不重复的元素)= 5 , 可以接受误差
实际应用
网页 UV(一个人访问一个网站多次,只算一次):
传统方式:SET保存用户 ID,然后对 ID 进行计算。这种方式如果数据量太大就是去了意义,以为目的是计数,并不是存所有的 ID。
基数统计:用户访问一次就放入 PF 中PFadd key a b c d e f a b c ,允许重复,统计的时候只需要使用PFCOUNT key即可。
如果允许容错,那么使用Hyperloglog是不错的选择;如果不允许容错就使用SET或者自己的数据类型。
Bitmap 位图
统计用户信息:活跃、不活跃;登录,未登录;打卡,365 打卡。都是操作二进制位来进行记录,就只有0和1两个状态。
例如:365 天每天对应一个bit,365 天 = 365bit ,那么占有内存大概就是45KB左右。哪天打卡,哪天设置为1。
事务
Redis单条命令是保证原子性的,但是事务是不保证原子性的。所有的命令在事务中没有被直接执行,直到EXEC被执行。事务中的所有命令都会被序列化,事务执行过程中会按照顺序执行,事务执行过程中具有排他性。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
127.0.0.1:6379> MULTI #事务开始
OK
127.0.0.1:6379(TX)> set k1 value1
QUEUED
127.0.0.1:6379(TX)> set k2 value2
QUEUED
127.0.0.1:6379(TX)> get k1
QUEUED
127.0.0.1:6379(TX)> EXEC #执行事务
1) OK
2) OK
3) "value1"
127.0.0.1:6379>
|
事务命令入队中,某个命令失败了,则整个事务执行报错:
1
2
3
4
5
6
7
8
9
|
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> set k1 v1
QUEUED
127.0.0.1:6379(TX)> set k1
(error) ERR wrong number of arguments for 'set' command
127.0.0.1:6379(TX)> EXEC
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379>
|
事务中某个命令执行时出错,该命令失败,其他命令不会失败:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
127.0.0.1:6379> SET key1 "hello"
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> INCR key1 #此句会报错
QUEUED
127.0.0.1:6379(TX)> set key2 value2
QUEUED
127.0.0.1:6379(TX)> get key2
QUEUED
127.0.0.1:6379(TX)> EXEC
1) (error) ERR value is not an integer or out of range #此命令会执行失败
2) OK
3) "value2"
127.0.0.1:6379>
|
录入命令过程中,取消事务:
1
2
3
4
5
6
7
8
9
10
|
127.0.0.1:6379> SET k11 "hello world"
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> set k11 "hi brein!!"
QUEUED
127.0.0.1:6379(TX)> DISCARD #取消事务后,事务中的命令不会生效
OK
127.0.0.1:6379> get k11
"hello world"
|
悲观锁
认为什么时候都会出错,无论做什么都会加锁。
乐观锁
认为什么时候都不会出错,所以不会上锁,更新数据时判断在此期间是否有修改这个数据。
利用WATCH
获取 Version,更新时比较 Version
正常执行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set out 0
OK
127.0.0.1:6379> watch money #监视
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> decrby money 20
QUEUED
127.0.0.1:6379(TX)> incrby money 10
QUEUED
127.0.0.1:6379(TX)> EXEC
1) (integer) 80
2) (integer) 90
|
开启另一个进程,测试多线程修改值, 使用WATCH当作乐观锁:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
#client #1
127.0.0.1:6379> incrby money 10 #2)修改money
(integer) 100
127.0.0.1:6379> get money
"100"
#client #2
127.0.0.1:6379> keys *
1) "out"
2) "money"
127.0.0.1:6379> get money
"90"
127.0.0.1:6379> watch money #1)监视money
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> incrby money 10
QUEUED
127.0.0.1:6379(TX)> EXEC
(nil) #事务的执行会失败,因为watch监测到money有过修改(version不一致),所以事务不会执行
#若要继续执行该操作,需要解锁unwatch,再watch,再执行
127.0.0.1:6379> UNWATCH
OK
127.0.0.1:6379> WATCH money
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> incrby money 10
QUEUED
127.0.0.1:6379(TX)> EXEC
1) (integer) 110
|
乐观锁可以使用在:秒杀的场景
Redis 进阶
Redis 持久化
Redis是内存数据库,如果不将内容中的数据保存到磁盘中,一旦服务崩溃,数据就会丢失,所以持久化是必须要有的。下面介绍了两种持久化方案:
RDB(Redis Database)
在指定的事件内将内存中的数据快照写入磁盘(dump.rdb),恢复时就是直接将磁盘快照中的数据读入内存。Redis会单独创建(fork)一个子进程来进行持久化,会先把数据缓存到一个临时文件中,当本次持久化操作完成后,再把缓存替换调上次的快照文件。整个过程中,主进程不进行任何 IO 操作,保证了性能。如果需要大规模的数据恢复,但对应于数据恢复的完整性不太敏感,那么RDB的方式要比之后要介绍的AOF方式更加高效。RDB的缺点就是,最后一次持久化的数据可能丢失。默认情况下就是RDB,配置如下:
1
2
3
4
|
#指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合
save 900 1 # 900 秒(15 分钟)内有 1 个更改
save 300 10 # 300 秒(5 分钟)内有 10 个更改
save 60 1000 # 60 秒内有 10000 个更改
|
触发机制:
- 满足配置文件的配置时,会自动触发
- 执行 flushall 命令时,会自动触发
- 退出
Redis时,也会触发
查看位置:
1
2
3
|
127.0.0.1:6379> config get dir
1) "dir"
2) "/usr/local/bin" #如果次目录下有dump.rdb文件,启动就会恢复其中的数据
|
AOF(Append Only File)
将所有命令都以日志的形式记录下来,相当于 history 文件,所以比RDB慢。注意, 只记录写操作,读操作不记录,Redis启动时就会读取该文件,把里面的内容全部执行一遍,完成数据恢复。保存的是appendonly.aof文件。默认不开启,开启的配置:
1
2
3
4
5
6
|
appendonly yes #只把此项改为yes即可,其他默认
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
|
发布订阅
Redis发布订阅(pub/sub)是一种消息通信模式:发送者发消息到指定的频道(channel),订阅者接受指定频道的消息。客户端可以订阅任意数量的频道。本节参考菜鸟教程,图示如下:
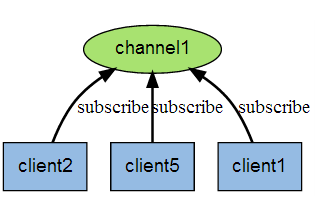
上图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系。当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
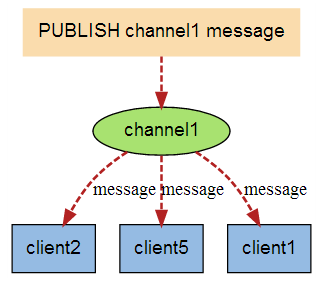
此处的应用很广泛,比如,我们经常遇到这样一个常见,我们平时火车购票,外卖下单,都会提示一个多少事件订单失效的倒计时,这个就是利用Redis做的,当键失效的时候,Redis会发消息给对应的频道(__keyevent@0__:expired),我们的程序只要订阅了这个频道,就可以收到消息,继而可以处理失效的订单。另外,网络聊天室等也可以实现。
1
2
3
4
5
6
7
8
|
#第一个client
SUBSCRIBE __keyevent@0__:expired
#第二个client
SUBSCRIBE __keyevent@0__:expired
#Redis
PUBLISH __keyevent@0__:expired # @ 后的数字表示数据库id 0库的任何过期事件都会发到该channel中
|
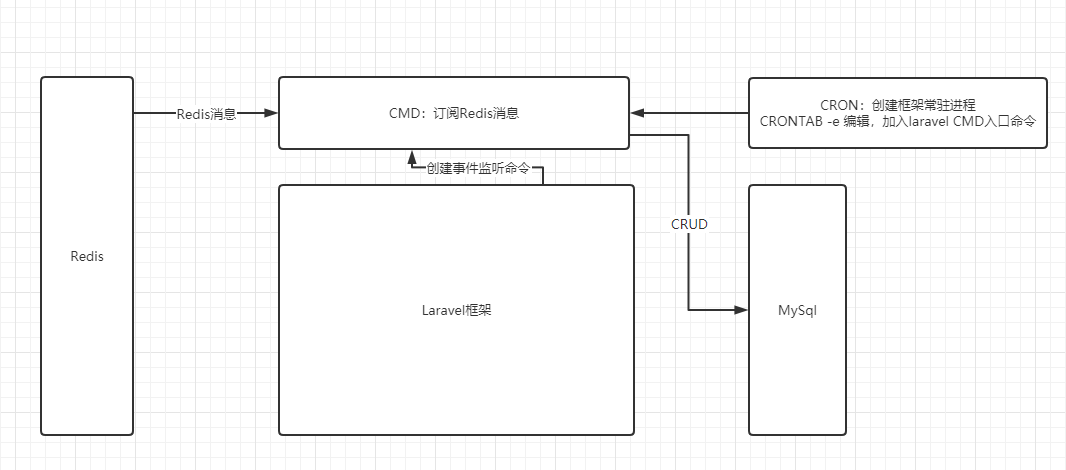
以laravel框架为例,订单失效处理示意图如下:
对于每个修改数据库的操作,键空间通知都会发送两种不同类型的事件消息:keyspace 和 keyevent。以 keyspace 为前缀的频道被称为键空间通知(key-space notification), 而以 keyevent 为前缀的频道则被称为键事件通知(key-event notification)。事件是用 __keyspace@DB__:KeyPattern 或者 __keyevent@DB__:OpsType 的格式来发布消息的。
DB 表示在第几个库;KeyPattern则是表示需要监控的键模式(可以用通配符,如:__key*__:*);OpsType则表示操作类型。因此,如果想要订阅特殊的 Key 上的事件,应该是订阅keyspace。比如说,对 0 号数据库的键 sampleKey 执行DEL命令时, 系统将分发两条消息, 相当于执行以下两个 PUBLISH 命令:
1
2
|
PUBLISH keyspace@0:sampleKey del
PUBLISH keyevent@0:del sampleKey
|
订阅第一个频道 __keyspace@0__:mykey 可以接收 0 号数据库中所有修改键 sampleKey的事件, 而订阅第二个频道__keyevent@0__:del则可以接收 0 号数据库中所有执行 del 命令的键。由于键空间通知比较耗CPU, 所以 Redis默认是关闭键空间事件通知的, 需要手动开启 notify-keyspace-events 后才启作用:
1
|
notify-keyspace-events Ex #表示开启键过期事件提醒
|
相关配置项如下:
| 字符 |
发送通知 |
| K |
键空间通知,所有通知以 keyspace@ 为前缀,针对 Key |
| E |
键事件通知,所有通知以 keyevent@ 为前缀,针对 event |
| g |
DEL 、 EXPIRE 、 RENAME 等类型无关的通用命令的通知 |
| $ |
字符串命令的通知 |
| l |
列表命令的通知 |
| s |
集合命令的通知 |
| h |
哈希命令的通知 |
| z |
有序集合命令 |
| x |
过期事件(每次 key 过期时生成) |
| e |
驱逐事件(当 key 在内存满了被清除时生成) |
| A |
g$lshzxe 的别名,因此”AKE”意味着所有的事件 |
Redis 集群
Redis 主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master/leader),后者成为从节点(slave/follower)。数据的复制是单向的,只能从主节点复制到从节点。主节点以写为主,从节点以读为主。
主从复制的作用主要包括:
- 数据冗余:主从复制实现的数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点楚问题时,可以由从节点继续提供服务。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供些服务,从节点提供读服务,分担服务器负载,尤其是在写少读多的场景下,通过多个从节点负担读负载,可以大大提高
Redis服务器的并发量。
- 高可用基石:主从复制还是哨兵、集群能够实施的基础。
一般来说,项目中会使用多个Redis服务器,不会只用一台服务器,最少一主二从。一般单台Redis服务器最大使用内存不应该超过 20G。
哨兵模式
哨兵模式是一种特殊的模式,Redis提供了哨兵的命令,哨兵是一个独立的进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器的响应,从而监控运行的多个Redis实例。如果主服务器崩溃,会利用自己的机制将从服务器设置为主服务器,即使之前的主服务器回来了,也只能作为现在主服务器的从服务器。

当然,在实际项目中,也不可能只有一个哨兵,一定是多个哨兵,多个服务器的配置。如下图:
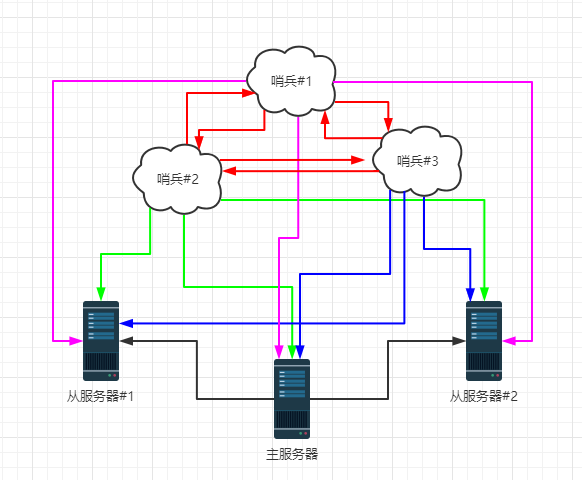
多哨兵模式,各个哨兵之间也会进行监控。尽最大可能保证高可用。当主服务器宕机,哨兵 1 先检测到这个结果 ,系统并不会进行进一步处理(failover过程),仅仅是哨兵 1 主观上认为主服务器出错,这个现象称为主观下线,当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,哨兵之间会进行投票,投票的结果由一个哨兵发起,进行故障转移(failover)操作。切换成功后,就会通过发布订阅模式,让各个哨兵把该从服务器切换为主服务器,这个过程叫做客观下线。
(全文完)
